
Новітня мовна модель Grok 4, розроблена компанією xAI Ілона Маска, привернула значну увагу технологічної спільноти завдяки опублікованим неофіційним даним щодо її продуктивності. На різних онлайн-платформах активно обговорюють бенчмарки Grok 4, які з’явилися у відкритому доступі завдяки акаунту @legit_api. Цей акаунт раніше вже публікував достовірні витоки про інші штучні інтелекти, що підвищує довіру до представленої інформації.
Про це розповідає ProIT
Вражаючі результати в Humanity Last Exam
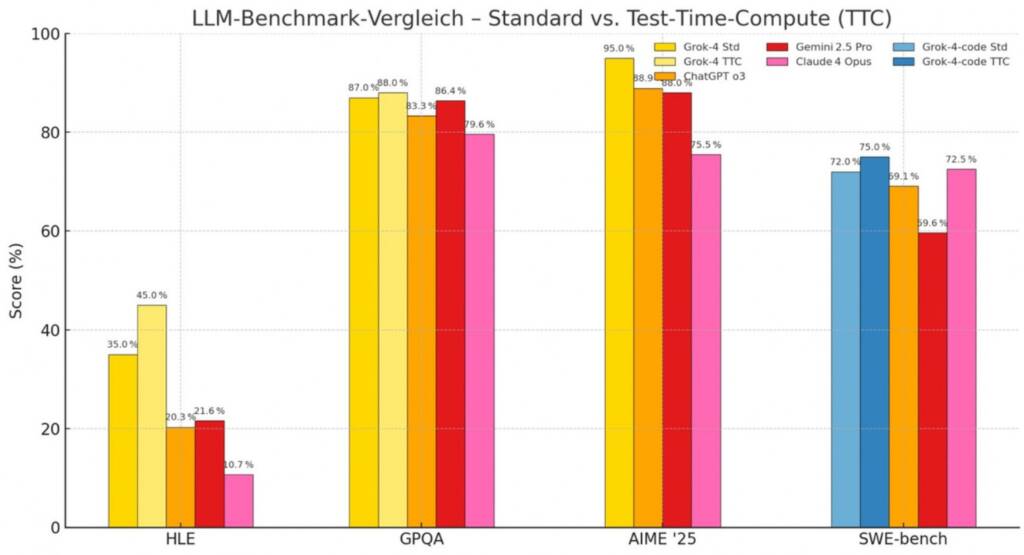
Особливої популярності набули результати Grok 4 у Humanity Last Exam (HLE) — випробуванні із 2500 складних питань з фізики, математики, права та інших наукових сфер, відповіді на які неможливо знайти простим пошуком в інтернеті. За оприлюдненими даними, Grok 4 продемонструвала продуктивність, що на 50% перевищує показники провідних конкурентів, зокрема ChatGPT o3 і Gemini 2.5 Pro. У тестах з програмування, біології та математики перевага моделі є менш вираженою, однак залишається стабільною.
“Згідно з витоком, Grok 4 впорався з ними в півтора рази краще, ніж нинішні лідери на кшталт ChatGPT o3 і Gemini 2.5 Pro.”
Дві модифікації та режими тестування
У представлений список тестів увійшли дві версії Grok 4: базова та спеціалізована для програмування. Тестування проводилося у двох режимах — Standard, який відповідає реальному використанню, та TTC, що демонструє теоретичний максимум моделі при необмежених ресурсах. Це дозволяє оцінити як практичні, так і потенційні можливості Grok 4 у різних сценаріях застосування.
Спочатку Grok 4 була презентована у квітні під назвою Grok 3.5, але згодом перейменована. Ілон Маск анонсував швидкий запуск моделі, однак згодом повідомив про потребу додаткового доопрацювання. Минулого тижня він зазначив, що реліз відбудеться «після 4 липня», проте станом на сьогодні офіційний запуск ще не відбувся.