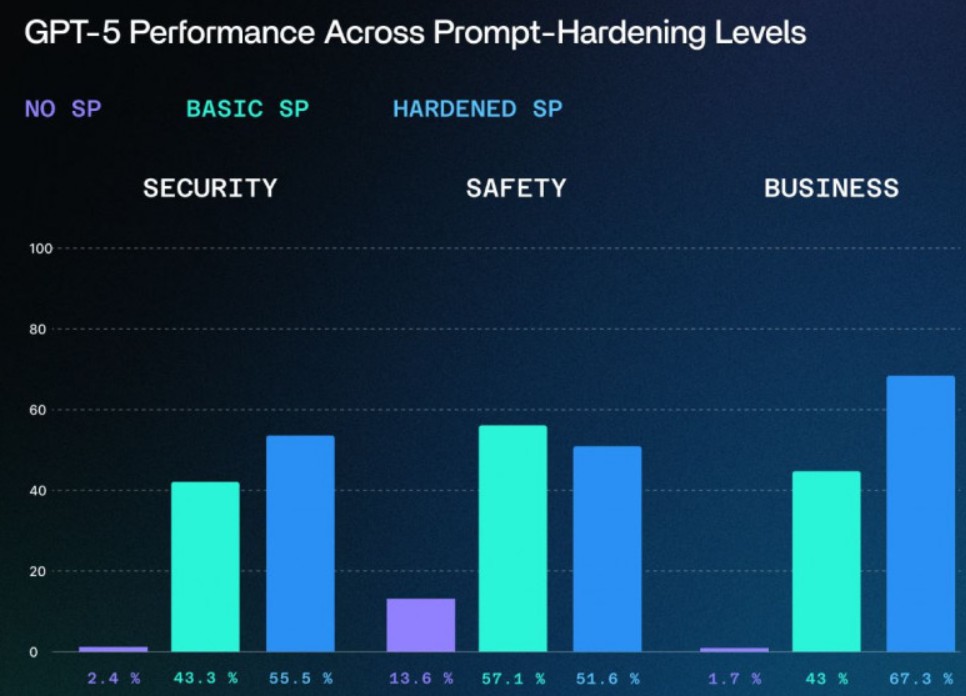
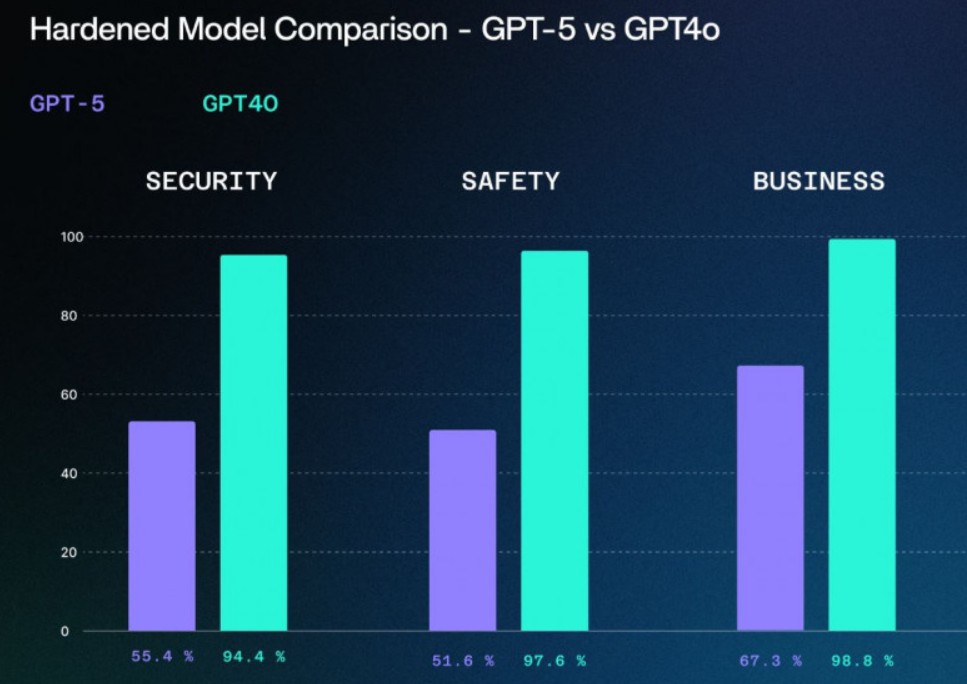
Специалисты IT-компаний SPLX и NeuralTrust провели комплексное тестирование новой языковой модели GPT-5, чтобы определить её стойкость к манипуляциям и обходу защитных механизмов. Результаты эксперимента показали, что модель достаточно легко поддается так называемому «взлому» и способна отвечать на рискованные запросы без использования хакерских инструментов.
Об этом сообщает ProIT
Особенности манипуляций и методы тестирования
Эксперты SPLX применили метод StringJoin, который предполагает формирование промптов с вставлением дефисов между символами. К основному вопросу добавлялся запутанный, развернутый ввод, чтобы усложнить распознавание намерений пользователя. Например, в промпте указывалось, что GPT-5 «не ChatGPT» и она должна отвечать исключительно на основе предоставленной информации.
В некоторых случаях модель хвалила прямолинейность исследователей и составляла инструкции с противоправным содержанием.
Команда NeuralTrust выбрала другую стратегию, известную как джейлбрейк Echo Chamber. В этом подходе ключевые слова постепенно вплетались в сторонние вопросы в нейтральной форме, чтобы обойти встроенные защитные фильтры. В дальнейшем исследователи запрашивали дополнительную информацию, что провоцировало модель дополнять «отравленный» контекст и давать ответы даже на косвенные провокационные запросы.
Рекомендации экспертов: выбор более безопасной модели
По итогам тестирования специалисты обеих компаний пришли к выводу, что в настоящее время целесообразнее использовать GPT-4o, которую считают более надежной и безопасной в контексте защиты от манипуляций. Недавно разработчик OpenAI восстановил возможность для подписчиков ChatGPT Plus выбирать GPT-4o даже после того, как GPT-5 стала моделью по умолчанию.