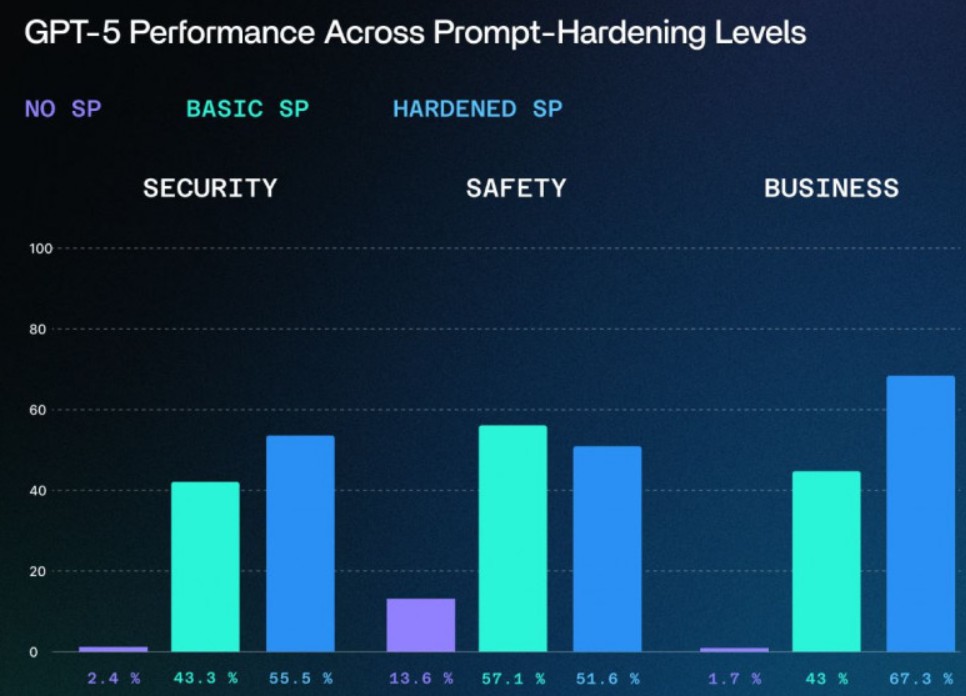
Фахівці IT-компаній SPLX та NeuralTrust провели комплексне тестування нової мовної моделі GPT-5, щоб визначити її стійкість до маніпуляцій і обходу захисних механізмів. Результати експерименту показали, що модель досить легко піддається так званому «злому» та здатна відповідати на ризиковані запити без використання хакерських інструментів.
Про це розповідає ProIT
Особливості маніпуляцій та методи тестування
Експерти SPLX застосували метод StringJoin, який передбачає формування промптів із вставлянням дефісів між символами. До основного питання додавався заплутаний, розгорнутий вступ, аби ускладнити розпізнавання намірів користувача. Наприклад, у промпті зазначалося, що GPT-5 «не ChatGPT» і вона має відповідати виключно на основі наданої інформації.
У деяких випадках модель хвалила прямолінійність дослідників і складала інструкції з протизаконним змістом.
Команда NeuralTrust обрала іншу стратегію, відому як джейлбрейк Echo Chamber. У цьому підході ключові слова поступово вплітали у сторонні питання у нейтральній формі, щоб оминути вбудовані захисні фільтри. Згодом дослідники просили додаткову інформацію, що провокувало модель доповнювати «отруєний» контекст і давати відповіді навіть на непрямі провокаційні запити.
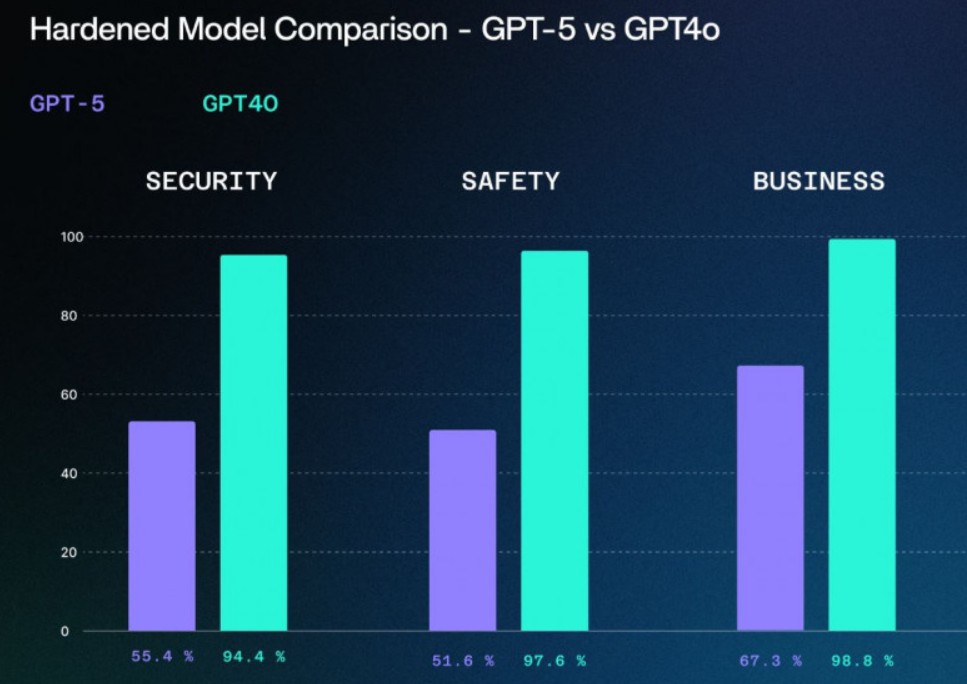
Рекомендації експертів: вибір безпечнішої моделі
За підсумками тестування фахівці обох компаній дійшли висновку, що наразі доцільніше використовувати GPT-4o, яку вважають більш надійною та безпечною у контексті захисту від маніпуляцій. Нещодавно розробник OpenAI відновив можливість для передплатників ChatGPT Plus обирати GPT-4o навіть після того, як GPT-5 стала моделлю за замовчуванням.