
Китайський стартап з розробки штучного інтелекту MiniMax представив свою нову відкриту LLM-модель для програмування – MiniMax-M1, яка вже отримала популярність завдяки реалістичній генерації відео з використанням моделі Hailuo. MiniMax-M1 доступна для комерційного використання та розповсюджується під ліцензією Apache 2.0, що дозволяє компаніям вільно впроваджувати її у свої продукти, змінювати та розширювати функціонал без обмежень.
Про це розповідає ProIT
Особливості та переваги MiniMax-M1
Основною перевагою MiniMax-M1 є рекордне контекстне вікно у 1 мільйон вхідних токенів та можливість генерувати до 80 тисяч токенів на виході. Це одна з найбільших моделей у сфері контекстного мислення: для порівняння, у GPT-4o від OpenAI цей показник становить лише 128 000 токенів, що еквівалентно обсягу одного роману. MiniMax-M1 може обробляти обсяг, співмірний з цілою бібліотекою невеликих книг за одну сесію. Google Gemini 2.5 Pro також досяг позначки у 1 млн токенів, а для майбутньої версії вже готують контекст на 2 млн токенів.
Модель MiniMax-M1 має відкритий код і доступна на платформах Hugging Face та Microsoft GitHub. Вона пропонується у версіях MiniMax-M1-40k та MiniMax-M1-80k, які відрізняються розміром вихідних даних.
Технічні характеристики та ефективність навчання
Відповідно до технічного звіту, MiniMax-M1 споживає лише 25% обчислювальних FLOP у порівнянні з DeepSeek R1 при генерації 100 000 токенів. Архітектура побудована на базі попередньої платформи MiniMax-Text-01 і містить 456 мільярдів параметрів, з яких 45,9 мільярда активні для одного токена.
Процес навчання MiniMax-M1 відзначається інноваційністю завдяки використанню гібридної суміші експертів (MoE) із спеціальним механізмом блискавичної уваги, що значно знижує витрати на інференс. Вартість навчання моделі склала всього $534 700, що суттєво менше у порівнянні з іншими лідерами галузі: DeepSeek R1 обійшлася у $5,6 млн, а GPT-4 від OpenAI – понад $100 млн. За таку ефективність відповідає спеціалізований алгоритм CISPO, який оптимізує процес обрізки ваг вибірки важливості, а також гібридна конструкція уваги, що забезпечує масштабованість.
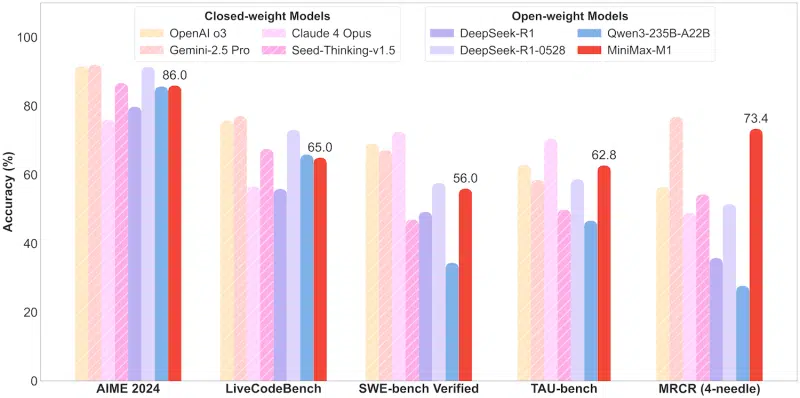
Реліз MiniMax-M1 став першим у серії анонсів MiniMaxWeek, що триватиме п’ять днів. Компанія вже повідомила у соцмережі X про свої амбітні плани щодо подальших оновлень та нових продуктів.
“We’re open-sourcing MiniMax-M1, our latest LLM — setting new standards in long-context reasoning. World’s longest context window: 1M-token input, 80k-token output — State-of-the-art agentic use among open-source models — RL at unmatched efficiency:…”